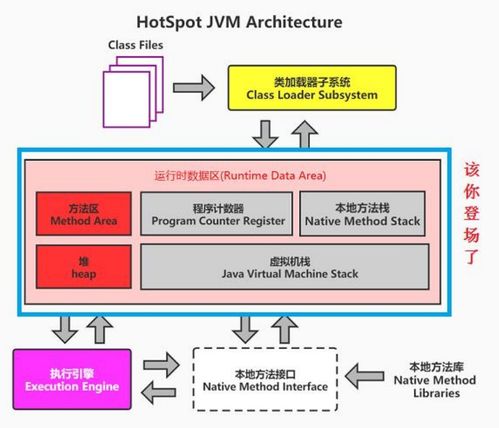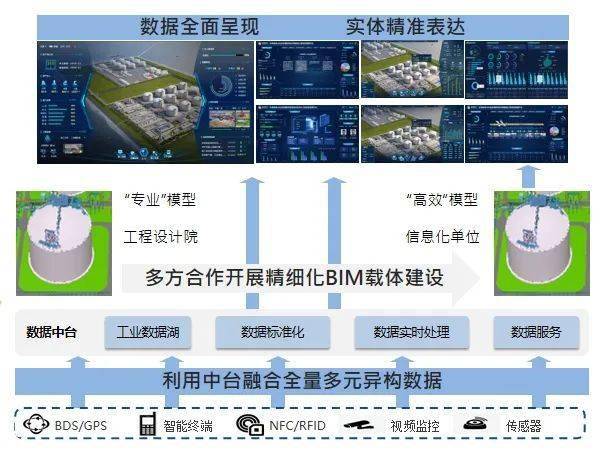
在數(shù)據(jù)驅(qū)動的時代,企業(yè)面臨著處理海量數(shù)據(jù)并從中快速提取價值的巨大挑戰(zhàn)。傳統(tǒng)的數(shù)據(jù)架構(gòu)通常將批處理與流處理割裂,導(dǎo)致數(shù)據(jù)孤島、處理延遲高、維護(hù)成本巨大以及數(shù)據(jù)一致性難以保證。Apache Hudi(Hadoop Upserts Deletes and Incrementals)應(yīng)運(yùn)而生,作為一個開源的數(shù)據(jù)存儲框架,它旨在統(tǒng)一批處理和近實(shí)時分析的數(shù)據(jù)處理范式,為現(xiàn)代數(shù)據(jù)湖提供高效、可靠的數(shù)據(jù)存儲與服務(wù)能力。
核心價值:統(tǒng)一的數(shù)據(jù)處理層
Apache Hudi的核心設(shè)計(jì)理念是構(gòu)建一個統(tǒng)一的數(shù)據(jù)處理層。它通過在分布式文件系統(tǒng)(如HDFS或云存儲)之上引入表格式抽象,原生支持高效的記錄級更新、刪除操作以及增量數(shù)據(jù)查詢。這意味著:
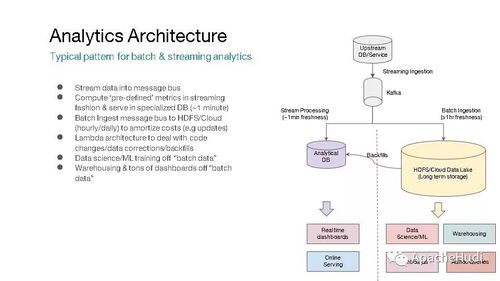
- 批流融合:傳統(tǒng)上,批處理作業(yè)(如每天一次的ETL)和流處理作業(yè)(如實(shí)時事件處理)使用不同的技術(shù)和存儲,導(dǎo)致數(shù)據(jù)冗余和同步復(fù)雜性。Hudi通過其“增量處理”模型,使得流式作業(yè)可以持續(xù)地將數(shù)據(jù)寫入Hudi表,而批處理作業(yè)可以隨時讀取包含最新更新的完整數(shù)據(jù)集或特定時間范圍內(nèi)的增量數(shù)據(jù)。兩者共享同一套存儲和表結(jié)構(gòu),實(shí)現(xiàn)了真正的批流一體。
- 近實(shí)時分析:Hudi支持低至幾分鐘的數(shù)據(jù)落地延遲。通過其“寫時合并”(Merge On Read)和“讀時合并”(Copy On Write)兩種表類型,用戶可以在數(shù)據(jù)新鮮度與查詢性能之間做出靈活權(quán)衡。例如,
Merge On Read表允許實(shí)時數(shù)據(jù)快速寫入日志文件,后臺再異步合并到列式存儲文件中,從而實(shí)現(xiàn)對新數(shù)據(jù)的近實(shí)時查詢。
關(guān)鍵技術(shù)與數(shù)據(jù)處理能力
Hudi通過一系列關(guān)鍵技術(shù)賦能高效的數(shù)據(jù)處理與存儲服務(wù):
- 事務(wù)性保證:提供ACID事務(wù)支持,確保在并發(fā)讀寫場景下的數(shù)據(jù)一致性。每一次提交都生成一個全局有序的時間軸,記錄了表的所有變化,這是實(shí)現(xiàn)增量拉取和時間旅行查詢的基礎(chǔ)。
- 高效的更新與刪除:直接支持主鍵級別的
UPSERT(插入/更新)和DELETE操作,無需重寫整個分區(qū)或表。這極大地簡化了變更數(shù)據(jù)捕獲(CDC)場景、數(shù)據(jù)修正和數(shù)據(jù)合規(guī)(如GDPR刪除請求)的實(shí)現(xiàn)。
- 自動文件管理:通過自動壓縮(將小文件合并為更大、查詢高效的文件)、清理(清除舊版本數(shù)據(jù)以節(jié)省存儲)和聚類(優(yōu)化文件布局)等后臺服務(wù),自動維護(hù)存儲的健康狀態(tài)和查詢性能,降低了運(yùn)維負(fù)擔(dān)。
- 增量查詢管道:基于其強(qiáng)大的時間軸元數(shù)據(jù),Hudi能夠精確地提取自某個時刻以來發(fā)生變化的數(shù)據(jù)。這使得構(gòu)建高效的增量ETL管道變得異常簡單,下游系統(tǒng)(如數(shù)據(jù)倉庫、指標(biāo)系統(tǒng))只需消費(fèi)增量數(shù)據(jù),而非全量掃描,節(jié)省了大量計(jì)算資源。
作為數(shù)據(jù)存儲服務(wù)的優(yōu)勢
在數(shù)據(jù)存儲服務(wù)層面,Apache Hudi帶來了范式轉(zhuǎn)變:
- 服務(wù)化數(shù)據(jù)湖:它將原始的數(shù)據(jù)湖存儲(通常是文件集合)轉(zhuǎn)變?yōu)榫哂袛?shù)據(jù)庫式語義(增刪改查、事務(wù)、索引)的“服務(wù)化”表。數(shù)據(jù)工程師和科學(xué)家可以像操作數(shù)據(jù)庫表一樣與之交互。
- 多引擎兼容:Hudi與主流數(shù)據(jù)處理引擎深度集成,包括Apache Spark、Flink、Trino/Presto、Hive等。這意味著計(jì)算引擎可以各司其職(Spark/Flink用于寫入和ETL,Trino用于交互式查詢),但都基于同一份Hudi存儲,確保了數(shù)據(jù)的單一可信源。
- 提升數(shù)據(jù)新鮮度與效率:通過統(tǒng)一存儲,數(shù)據(jù)從產(chǎn)生到可用于分析的時間被大幅縮短。增量處理模式減少了不必要的數(shù)據(jù)重復(fù)計(jì)算和移動,提升了整體數(shù)據(jù)處理效率,降低了成本。
典型應(yīng)用場景
- 實(shí)時數(shù)據(jù)倉庫:將來自業(yè)務(wù)數(shù)據(jù)庫的CDC日志、應(yīng)用日志和實(shí)時事件流近實(shí)時地?cái)z入Hudi表,為BI和報表系統(tǒng)提供新鮮、統(tǒng)一的數(shù)據(jù)底座。
- 機(jī)器學(xué)習(xí)特征庫:為特征工程提供支持頻繁更新的特征存儲,確保訓(xùn)練和推理使用的特征數(shù)據(jù)是最新且一致的。
- 增量ETL與數(shù)據(jù)管道:簡化從操作型數(shù)據(jù)庫到分析型系統(tǒng)的數(shù)據(jù)同步流程,構(gòu)建高效、可靠的增量數(shù)據(jù)管道。
- 交互式查詢服務(wù):基于Hudi表提供對最新數(shù)據(jù)(包括剛更新或刪除的記錄)的低延遲查詢能力。
###
Apache Hudi不僅僅是一個存儲格式,更是一個旨在解決數(shù)據(jù)湖中數(shù)據(jù)管理痛點(diǎn)的綜合性平臺。它通過統(tǒng)一批處理和近實(shí)時分析的數(shù)據(jù)存儲與服務(wù)層,實(shí)現(xiàn)了數(shù)據(jù)處理的簡化和性能的飛躍。在構(gòu)建現(xiàn)代化、高效且易于維護(hù)的數(shù)據(jù)架構(gòu)時,Hudi為處理快速變化的海量數(shù)據(jù)提供了一個強(qiáng)大而靈活的解決方案,正成為企業(yè)解鎖數(shù)據(jù)實(shí)時價值的關(guān)鍵基石。